autoPipe Module¶
- Description :
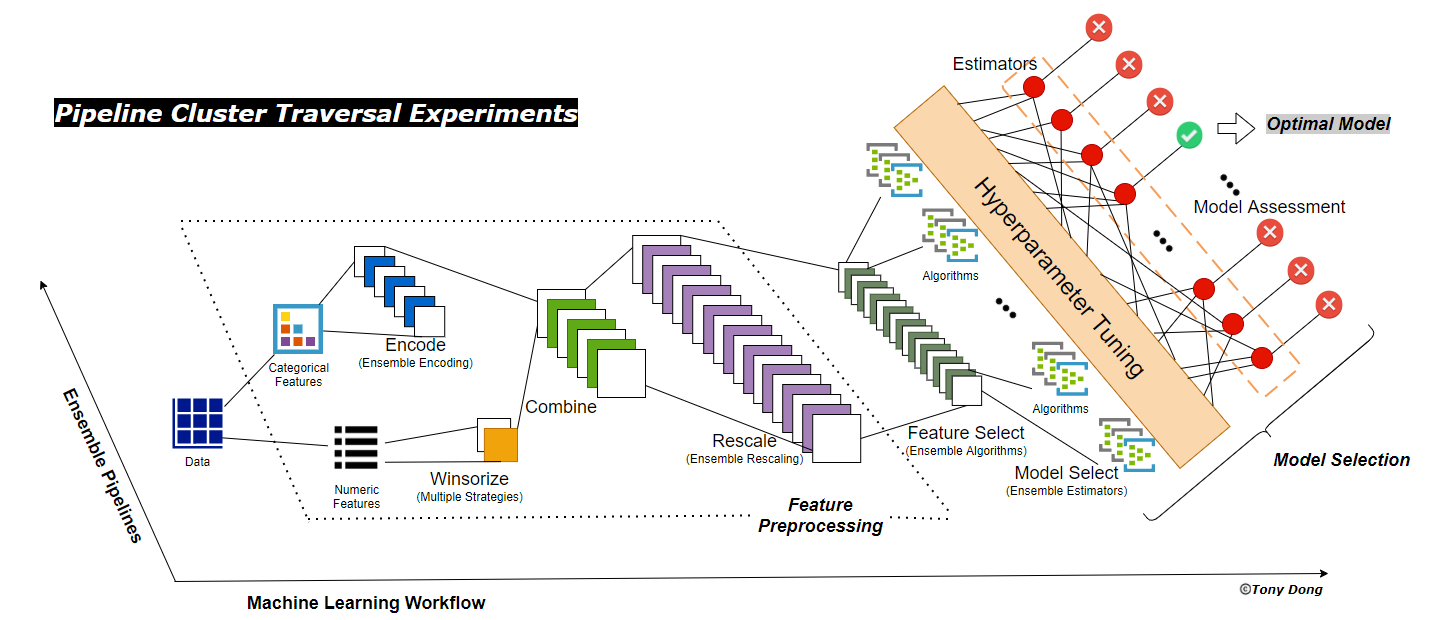
- This module is used to build Pipeline Cluster Traversal Experiments:
- Create sequential components of Pipeline Cluster Traversal Experiments
- Apply traversal experiments through pipeline cluster to find the best baseline model
- Generate comparable and parameter-tracable dictionaies and reports to support autoVIZ and autoFlow modules
- Build Steps:
- autoPP - dynaPreprocessing() Class in autoPP module
- Datasets Splitting - pipeline_splitting_rule() Function in utilis_funs module
- autoFS - dynaFS_clf() or dynaFS_reg() Class in autoFS module
- autoCV - dynaClassifier() or dynaRegressor() Class in autoCV module
- Model Evaluate - evaluate_model() Class in autoCV module
autoPipe¶
-
class
optimalflow.autoPipe.autoPipe(steps)[source]¶ This class is to build Pipeline Cluster Traversal Experiments.
Parameters: steps (list, default = None) – List of (name, transform) tuples (implementing fit & transform) that are chained, in the order in which they are chained, with the last object a model evaluation function. Example
[Example] https://Optimal-Flow.readthedocs.io/en/latest/demos.html#build-pipeline-cluster-traveral-experiments-using-autopipe References
None
-
fit(data)[source]¶ Fits and transforms a chain of Optimal Flow modules.
Parameters: input_data (pandas dataframe, shape = [n_samples, n_features]) – NOTE: The input_data should be the datasets after basic data cleaning & well feature deduction, the more features involve will result in more columns permutation outputs. Returns: - DICT_PREP_INFO (dictionary) – Each key is the # of preprocessed dataset(“Dataset_xxx” format, i.e. “Dataset_10”), each value stores an info string about what transforms applied. i.e. DICT_PREPROCESSING[‘Dataset_0’] stores value “winsor_0-Scaler_None– Encoded Features:[‘diagnosis’, ‘Size_3’, ‘area_mean’]”, which means applied 1st mode of winsorization, none scaler applied, and the encoded columns names(shown the enconding approachs in the names)
- DICT_FEATURE_SELECTION_INFO (dictionary) – Each key is the # of preprocessed dataset, each value stores the name of features selected after the autoFS module.
- DICT_MODELS_EVALUATION (dictionary) – Each key is the # of preprocessed dataset, each value stores the model evaluation results with its validate dataset.
- DICT_DATA (dictionary) – Each key is the # of preprocessed dataset, and first level sub-key is the type of splitted sets(including ‘DICT_Train’,’DICT_TEST’,and’DICT_Validate’). The second level sub-key is “X” for features and “y” for label, each value stores the datasets related to the keys(Pandas Dataframe format) i.e. DICT_DATA[‘Dataset_0’][‘DICT_TEST’][“X”] is the train features of Dataset_0’s test dataset
- models_summary (Pandas Dataframe) – Model selection results ranking table among all composits of preprocessed datasets, selected features and all posible models with optimal parameters.
- NOTE - Log records will generate and save to ./logs folder automatedly.
-