Examples¶
Feature preprocessing for a regression problem using autoPP:¶
Demo Code:
import pandas as pd
from optimalflow.funcPP import PPtools
from optimalflow.autoPP import dynaPreprocessing
df = pd.read_csv('../data/preprocessing/breast_cancer.csv')
custom_parameters = {
"scaler" : ["None", "standard"],
# threshold number of category dimension
"encode_band" : [6],
# low dimension encoding
"low_encode" : ["onehot","label"],
# high dimension encoding
"high_encode" : ["frequency", "mean"],
"winsorizer" : [(0.1,0.1)],
"sparsity" : [0.4862],
"cols" : [27]
}
dyna = dynaPreprocessing(custom_parameters = custom_parameters, label_col = 'diagnosis', model_type = "reg")
dict_df = dyna.fit(input_data = df)
print(f"Total combinations: {len(dict_df.keys())}")
print(dict_df['winsor_0-Scaler_standard-Dataset_441'])
Output:
Now in Progress - Data Preprocessing Ensemble Iteration: Estimate about 0
Total combinations: 64
diagnosis Size_3 area_mean compactness_mean concave points_mea
0 1 1.290564 1.151477 1.730765 1.63873
1 1 -1.423416 1.823311 -0.679975 0.53514
2 1 -0.066426 1.823311 1.163585 1.63873
3 1 1.290564 -1.011406 1.730765 1.63873
4 1 -0.066426 1.823311 0.548763 1.61037
.. ... ... ... ... ..
281 0 -0.066426 -0.866487 -1.300016 -0.80503
282 1 -0.066426 1.657991 0.807396 1.30604
283 1 -0.066426 0.462408 1.624135 1.17625
284 0 -0.066426 -0.552378 -0.290663 -0.60750
285 0 1.290564 -0.649460 -1.300016 -1.25679
[286 rows x 26 columns]
Features selection for a regression problem using autoFS:¶
Demo Code:
# Demo - Regression
import pandas as pd
from optimalflow.autoFS import dynaFS_reg
# Boston Housing Cleaned dataset
tr_features = pd.read_csv('./data/regression/train_features.csv')
tr_labels = pd.read_csv('./data/regression/train_labels.csv')
# Set input_form_file = False, when label values are array. Select 'True' from Pandas dataframe.
reg_fs_demo = dynaFS_reg( fs_num = 5,random_state = 13,cv = 5,input_from_file = True)
# You can find details of each selector's choice in autoFS_logxxxxx.log file in the ./test folder
reg_fs_demo.fit(tr_features,tr_labels)
Output:
*optimalflow* autoFS Module ===> Selector kbest_f gets outputs: ['INDUS', 'NOX', 'RM', 'PTRATIO', 'LSTAT']
Progress: [###-----------------] 14.3%
*optimalflow* autoFS Module ===> Selector rfe_svm gets outputs: ['CHAS', 'NOX', 'RM', 'PTRATIO', 'LSTAT']
Progress: [######--------------] 28.6%
*optimalflow* autoFS Module ===> Selector rfe_tree gets outputs: ['CRIM', 'RM', 'DIS', 'TAX', 'LSTAT']
Progress: [#########-----------] 42.9%
*optimalflow* autoFS Module ===> Selector rfe_rf gets outputs: ['CRIM', 'RM', 'DIS', 'PTRATIO', 'LSTAT']
Progress: [###########---------] 57.1%
*optimalflow* autoFS Module ===> Selector rfecv_svm gets outputs: ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
Progress: [##############------] 71.4%
*optimalflow* autoFS Module ===> Selector rfecv_tree gets outputs: ['CRIM', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'TAX', 'PTRATIO', 'B', 'LSTAT']
Progress: [#################---] 85.7%
*optimalflow* autoFS Module ===> Selector rfecv_rf gets outputs: ['CRIM', 'ZN', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT']
Progress: [####################] 100.0%
The optimalflow autoFS identify the top 5 important features for regression are: ['RM', 'LSTAT', 'PTRATIO', 'NOX', 'CRIM'].
Here’s static notebook demo:
https://github.com/tonyleidong/OptimalFlow/blob/master/tests/autoFS_demo.ipynb
or Live Notebook Demo on Binder:
Model selection for a classification problem using autoCV:¶
NOTE: This Demo is using dynaClassifier class, which is grid search based; alternatively, you can use fastClassifier class instead, which is random search based, although that’s a kind of trades off runtime vs quality of the solution (See more details in autoCV module).
Demo Code:
import pandas as pd
from optimalflow.autoCV import dynaClassifier,evaluate_clf_model
import joblib
tr_features = pd.read_csv('./data/classification/train_features.csv')
tr_labels = pd.read_csv('./data/classification/train_labels.csv')
val_features = pd.read_csv('./data/classification/val_features.csv')
val_labels = pd.read_csv('./data/classification/val_labels.csv')
# We customize models cadidates for this demo:
custom_cv = ['lgr','svm','mlp','rf','ada','gb','xgb']
# Set input_form_file = False, when label values are array. Select 'True' from Pandas dataframe.
clf_cv_demo = dynaClassifier(custom_estimators = custom_cv, random_state = 13,cv_num = 5,input_from_file = True)
# Select detail_info = True, when you want to see the detail of the iteration
clf_cv_demo.fit(tr_features,tr_labels)
models = {}
for mdl in ['lgr','svm','mlp','rf','ada','gb','xgb']:
models[mdl] = joblib.load('./pkl/{}_clf_model.pkl'.format(mdl))
for name, mdl in models.items():
evaluate_clf_model(name, mdl, val_features, val_labels)
Output:
*OptimalFlow* autoCV Module ===> lgr_CrossValidation with 5 folds:
Best Parameters: {'C': 1, 'random_state': 13}
Best CV Score: 0.7997178628107917
Progress: [###-----------------] 14.3%
*OptimalFlow* autoCV Module ===> svm_CrossValidation with 5 folds:
Best Parameters: {'C': 0.1, 'kernel': 'linear'}
Best CV Score: 0.7959619114794568
Progress: [######--------------] 28.6%
*OptimalFlow* autoCV Module ===> mlp_CrossValidation with 5 folds:
Best Parameters: {'activation': 'tanh', 'hidden_layer_sizes': (50,), 'learning_rate': 'constant', 'random_state': 13, 'solver': 'lbfgs'}
Best CV Score: 0.8184094515958386
Progress: [#########-----------] 42.9%
*OptimalFlow* autoCV Module ===> rf_CrossValidation with 5 folds:
Best Parameters: {'max_depth': 4, 'n_estimators': 250, 'random_state': 13}
Best CV Score: 0.8240521953800035
Progress: [###########---------] 57.1%
*OptimalFlow* autoCV Module ===> ada_CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.1, 'n_estimators': 100, 'random_state': 13}
Best CV Score: 0.824034561805678
Progress: [##############------] 71.4%
*OptimalFlow* autoCV Module ===> gb_CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.01, 'max_depth': 3, 'n_estimators': 300, 'random_state': 13}
Best CV Score: 0.8408746252865456
Progress: [#################---] 85.7%
*OptimalFlow* autoCV Module ===> xgb_CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 200, 'verbosity': 0}
Best CV Score: 0.8464292011990832
Progress: [####################] 100.0%
lgr -- Accuracy: 0.775 / Precision: 0.712 / Recall: 0.646 / Latency: 0.0ms
svm -- Accuracy: 0.747 / Precision: 0.672 / Recall: 0.6 / Latency: 2.0ms
mlp -- Accuracy: 0.787 / Precision: 0.745 / Recall: 0.631 / Latency: 4.1ms
rf -- Accuracy: 0.809 / Precision: 0.83 / Recall: 0.6 / Latency: 37.0ms
ada -- Accuracy: 0.792 / Precision: 0.759 / Recall: 0.631 / Latency: 21.4ms
gb -- Accuracy: 0.815 / Precision: 0.796 / Recall: 0.662 / Latency: 2.0ms
xgb -- Accuracy: 0.815 / Precision: 0.786 / Recall: 0.677 / Latency: 5.0ms
Here’s static notebook demo:
https://github.com/tonyleidong/OptimalFlow/blob/master/tests/autoCV_clf_demo.ipynb
or Live Notebook Demo on Binder:
Model selection for a regression problem using autoCV:¶
NOTE: This Demo is using dynaRegressor class, which is grid search based; alternatively, you can use fastRegressor class instead, which is random search based, although that’s a kind of trades off runtime vs quality of the solution (See more details in autoCV module).
Demo Code:
import pandas as pd
from optimalflow.autoCV import evaluate_model,dynaClassifier,dynaRegressor
import joblib
from optimalflow.utilis_func import pipeline_splitting_rule, update_parameters,reset_parameters
reset_parameters()
tr_features = pd.read_csv('./data/regression/train_features.csv')
tr_labels = pd.read_csv('./data/regression/train_labels.csv')
val_features = pd.read_csv('./data/regression/val_features.csv')
val_labels = pd.read_csv('./data/regression/val_labels.csv')
te_features = pd.read_csv('./data/regression/test_features.csv')
te_labels = pd.read_csv('./data/regression/test_labels.csv')
reg_cv_demo = dynaRegressor(random_state=13,cv_num = 5)
reg_cv_demo.fit(tr_features,tr_labels)
models = {}
for mdl in ['lr','knn','tree','svm','mlp','rf','gb','ada','xgb','hgboost','huber','rgcv','cvlasso','sgd']:
models[mdl] = joblib.load('./pkl/{}_reg_model.pkl'.format(mdl))
for name, mdl in models.items():
try:
ml_evl = evaluate_model(model_type = "reg")
ml_evl.fit(name, mdl, val_features, val_labels)
except:
print(f"Failed to load the {mdl}.")
Output:
Done with the parameters reset.
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.0337 minutes left [#-------------------] 7.1%
*OptimalFlow* autoCV Module ===> lr model CrossValidation with 5 folds:
Best Parameters: {'normalize': False}
Best CV Score: 0.682929422892965
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.5549 minutes left [###-----------------] 14.3%
*OptimalFlow* autoCV Module ===> knn model CrossValidation with 5 folds:
Best Parameters: {'algorithm': 'auto', 'n_neighbors': 10, 'weights': 'distance'}
Best CV Score: 0.5277324478219082
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.2383 minutes left [####----------------] 21.4%
*OptimalFlow* autoCV Module ===> tree model CrossValidation with 5 folds:
Best Parameters: {'max_depth': 5, 'min_samples_leaf': 3, 'splitter': 'best'}
Best CV Score: 0.7704058399460141
Now in Progress - Model Selection w/ Cross-validation: Estimate about 11.0461 minutes left [######--------------] 28.6%
*OptimalFlow* autoCV Module ===> svm model CrossValidation with 5 folds:
Best Parameters: {'C': 1, 'kernel': 'linear'}
Best CV Score: 0.6817778239200576
Now in Progress - Model Selection w/ Cross-validation: Estimate about 20.2113 minutes left [#######-------------] 35.7%
*OptimalFlow* autoCV Module ===> mlp model CrossValidation with 5 folds:
Best Parameters: {'activation': 'identity', 'hidden_layer_sizes': (50,), 'learning_rate': 'constant', 'random_state': 13, 'solver': 'lbfgs'}
Best CV Score: 0.6556246414762388
Now in Progress - Model Selection w/ Cross-validation: Estimate about 3.1693 minutes left [#########-----------] 42.9%
*OptimalFlow* autoCV Module ===> rf model CrossValidation with 5 folds:
Best Parameters: {'max_depth': 8, 'n_estimators': 50}
Best CV Score: 0.8582920563031621
Now in Progress - Model Selection w/ Cross-validation: Estimate about 18.0094 minutes left [##########----------] 50.0%
*OptimalFlow* autoCV Module ===> gb model CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.2, 'max_depth': 3, 'n_estimators': 100}
Best CV Score: 0.8794018441486111
Now in Progress - Model Selection w/ Cross-validation: Estimate about 18.7663 minutes left [###########---------] 57.1%
*OptimalFlow* autoCV Module ===> ada model CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.3, 'loss': 'linear', 'n_estimators': 150, 'random_state': 13}
Best CV Score: 0.8255039215809923
Now in Progress - Model Selection w/ Cross-validation: Estimate about 4.545 minutes left [#############-------] 64.3%
*OptimalFlow* autoCV Module ===> xgb model CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.1, 'max_depth': 3, 'n_estimators': 300, 'verbosity': 0}
Best CV Score: 0.8645505523555148
Now in Progress - Model Selection w/ Cross-validation: Estimate about 1.6471 minutes left [##############------] 71.4%
*OptimalFlow* autoCV Module ===> hgboost model CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 0.2, 'max_depth': 3}
Best CV Score: 0.8490465745463796
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.0182 minutes left [################----] 78.6%
*OptimalFlow* autoCV Module ===> huber model CrossValidation with 5 folds:
Best Parameters: {'fit_intercept': False}
Best CV Score: 0.6250877399211718
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.0024 minutes left [#################---] 85.7%
*OptimalFlow* autoCV Module ===> rgcv model CrossValidation with 5 folds:
Best Parameters: {'fit_intercept': True}
Best CV Score: 0.6814764830347567
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.011 minutes left [###################-] 92.9%
*OptimalFlow* autoCV Module ===> cvlasso model CrossValidation with 5 folds:
Best Parameters: {'fit_intercept': True}
Best CV Score: 0.6686184981380419
Now in Progress - Model Selection w/ Cross-validation: Estimate about 0.0 minutes left [####################] 100.0%
*OptimalFlow* autoCV Module ===> sgd model CrossValidation with 5 folds:
Best Parameters: {'learning_rate': 'invscaling', 'penalty': 'elasticnet', 'shuffle': True}
Best CV Score: -1.445728757185719e+26
lr -- R^2 Score: 0.684 / Mean Absolute Error: 3.674 / Mean Squared Error: 24.037 / Root Mean Squared Error: 24.037 / Latency: 2.0s
knn -- R^2 Score: 0.307 / Mean Absolute Error: 4.639 / Mean Squared Error: 52.794 / Root Mean Squared Error: 52.794 / Latency: 3.0s
tree -- R^2 Score: 0.671 / Mean Absolute Error: 3.141 / Mean Squared Error: 25.077 / Root Mean Squared Error: 25.077 / Latency: 1.0s
svm -- R^2 Score: 0.649 / Mean Absolute Error: 3.466 / Mean Squared Error: 26.746 / Root Mean Squared Error: 26.746 / Latency: 7.0s
mlp -- R^2 Score: 0.629 / Mean Absolute Error: 3.56 / Mean Squared Error: 28.244 / Root Mean Squared Error: 28.244 / Latency: 4.0s
rf -- R^2 Score: 0.772 / Mean Absolute Error: 2.677 / Mean Squared Error: 17.327 / Root Mean Squared Error: 17.327 / Latency: 10.0s
gb -- R^2 Score: 0.775 / Mean Absolute Error: 2.616 / Mean Squared Error: 17.126 / Root Mean Squared Error: 17.126 / Latency: 1.0s
ada -- R^2 Score: 0.749 / Mean Absolute Error: 2.933 / Mean Squared Error: 19.09 / Root Mean Squared Error: 19.09 / Latency: 18.0s
xgb -- R^2 Score: 0.776 / Mean Absolute Error: 2.66 / Mean Squared Error: 17.02 / Root Mean Squared Error: 17.02 / Latency: 5.0s
hgboost -- R^2 Score: 0.758 / Mean Absolute Error: 2.98 / Mean Squared Error: 18.412 / Root Mean Squared Error: 18.412 / Latency: 9.2s
huber -- R^2 Score: 0.613 / Mean Absolute Error: 3.63 / Mean Squared Error: 29.476 / Root Mean Squared Error: 29.476 / Latency: 4.0s
rgcv -- R^2 Score: 0.672 / Mean Absolute Error: 3.757 / Mean Squared Error: 24.983 / Root Mean Squared Error: 24.983 / Latency: 3.0s
cvlasso -- R^2 Score: 0.661 / Mean Absolute Error: 3.741 / Mean Squared Error: 25.821 / Root Mean Squared Error: 25.821 / Latency: 4.0s
sgd -- R^2 Score: -7.6819521340367e+26 / Mean Absolute Error: 239048363331832.62 / Mean Squared Error: 5.849722584020232e+28 / Root Mean Squared Error: 5.849722584020232e+28 / Latency: 1.0s
Here’s static notebook demo:
https://github.com/tonyleidong/OptimalFlow/blob/master/tests/autoCV_reg_demo.ipynb
or Live Notebook Demo on Binder:
Custom estimators & parameters setting for for autoCV:¶
Currently, there’re 3 methods in utilis_fun module - reset_parameters, update_parameters, and export_parameters.
update_parameters method is used to modify the default parameter settings for models selection module (autoCV).
i.e. When you want to modify the support vector machine classifier, with new penalty “C” and “kernel” values, the code line below will achieve that.
update_parameters(mode = "cls", estimator_name = "svm", C=[0.1,0.2],kernel=["linear"])
- export_parameters method can help you export the currnt default parameter settings as 2 csv files named “exported_cls_parameters.csv” and “exported_reg_parameters.csv”. You can find them in the ./exported folder of you current work dictionary.
export_parameters()
- reset_parameters method can reset the default parameter settings to the package’s original default settings. Just add this code line will work:
reset_parameters()
Build Pipeline Cluster Traveral Experiments using autoPipe:¶
Demo Code:
import pandas as pd
from optimalflow.autoPipe import autoPipe
from optimalflow.funcPP import PPtools
from optimalflow.autoPP import dynaPreprocessing
from optimalflow.autoFS import dynaFS_clf
from optimalflow.autoCV import evaluate_model,dynaClassifier
df = pd.read_csv('./data/preprocessing/breast_cancer.csv')
pipe = autoPipe(
[("autoPP",dynaPreprocessing(custom_parameters = None, label_col = 'diagnosis', model_type = "cls")),
("datasets_splitting",pipeline_splitting_rule(val_size = 0.2, test_size = 0.2, random_state = 13)),
("autoFS",dynaFS_clf(fs_num = 5, random_state=13, cv = 5, in_pipeline = True, input_from_file = False)),
("autoCV",dynaClassifier(random_state = 13,cv_num = 5,in_pipeline = True, input_from_file = False)),
("model_evaluate",evaluate_model(model_type = "cls"))])
dyna_report= pipe.fit(df)[4]
dyna_report.head(5)
Output:
Dataset Model_Name Best_Parameters Accuracy Precision Recall Latency
1 Dataset_0 svm [('C', 0.1), ('kernel', 'linear')] 0.930 0.889 0.96 3.0
6 Dataset_0 xgb [('learning_rate', 1), ('max_depth', 2), ('n_estimators', 50), ('random_state', 13)] 0.912 0.955 0.84 2.0
40 Dataset_5 gb [('learning_rate', 1), ('max_depth', 2), ('n_estimators', 50), ('random_state', 13)] 0.895 0.913 0.84 2.0
31 Dataset_4 rf [('max_depth', 2), ('n_estimators', 50), ('random_state', 13)] 0.877 0.821 0.92 12.0
51 Dataset_7 mlp [('activation', 'relu'), ('hidden_layer_sizes', (10,)), ('learning_rate', 'constant'), ('random_state', 13), ('solver', 'sgd')] 0.772 0.875 0.56 4.0
Here’s static notebook demo:
https://github.com/tonyleidong/OptimalFlow/blob/master/tests/notebook_demo.ipynb
or Live Notebook Demo on Binder:
Pipeline Cluster Traversal Experiments Model Retrieval Diagram using autoViz:¶
NOTE: Current available for Classification Only.
Demo Code:
from optimalflow.autoViz import autoViz
viz = autoViz(preprocess_dict=DICT_PREPROCESSING,report=dyna_report)
viz.clf_model_retrieval(metrics='accuracy')
Output:

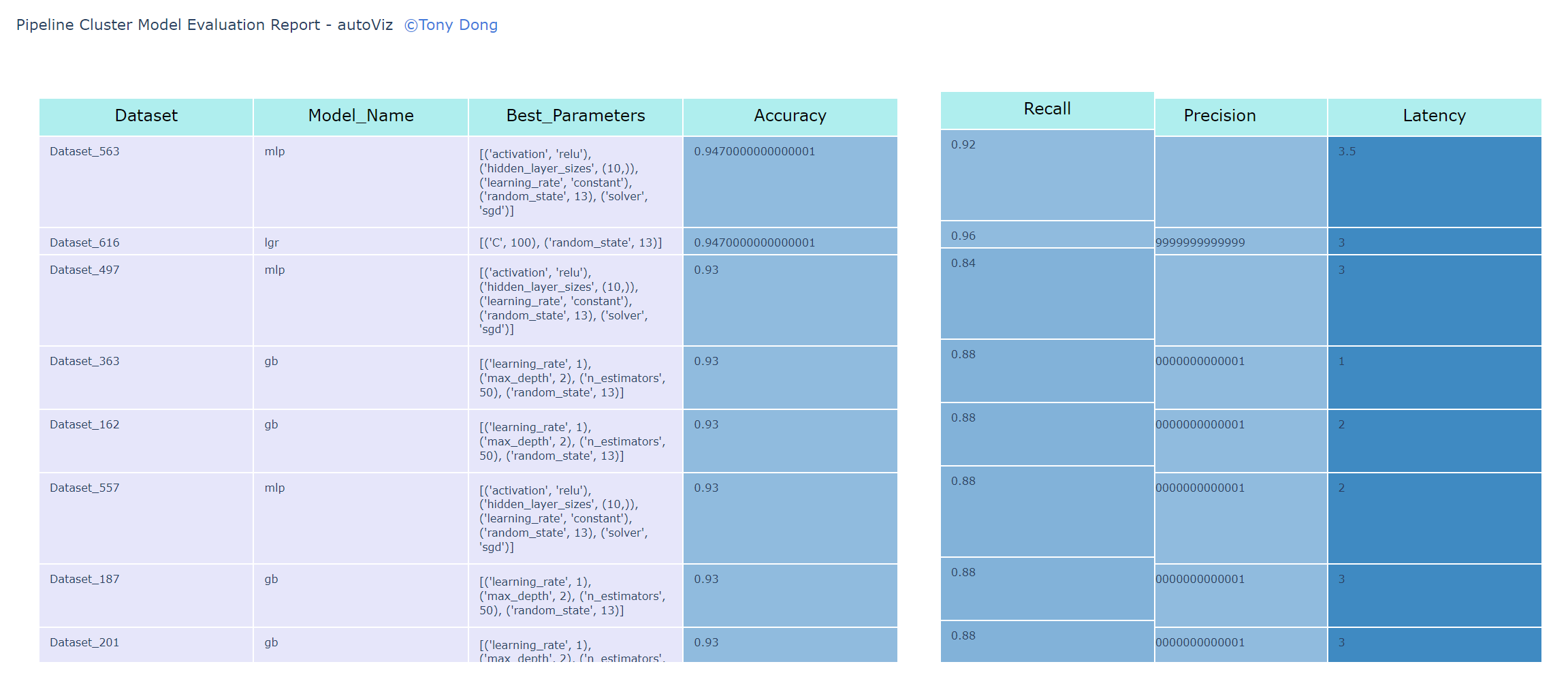
Pipeline Cluster Model Evaluation Dynamic Table using autoViz:¶
This demo is for classification problem. When it comes regression problem, use reg_table_report() instead.
Demo Code:
from optimalflow.autoViz import autoViz
viz = autoViz(report = dyna_report)
viz.clf_table_report()
Output:
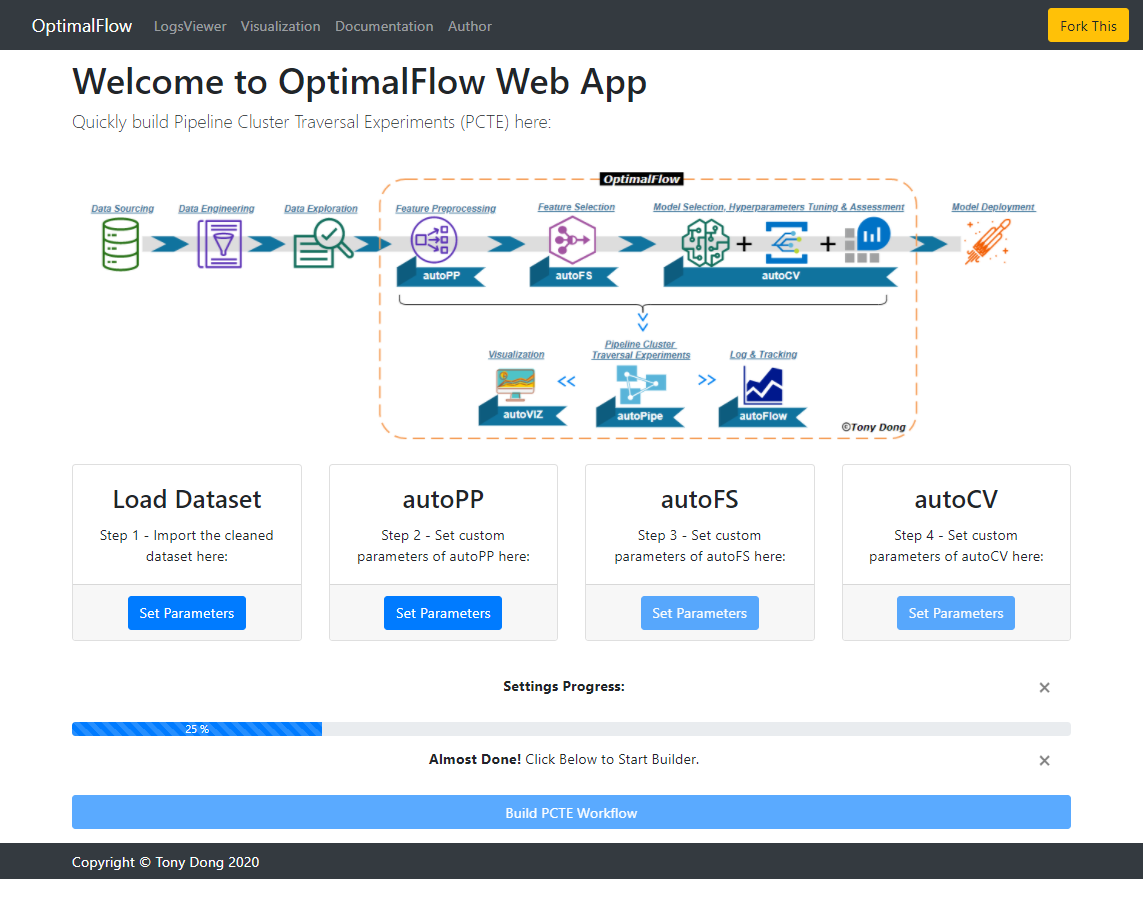
Build Pipeline Cluster Traversal Experiments Workflow with Web App:¶
See details in the ‘Web App’ page<https://optimal-flow.readthedocs.io/en/latest/webapp.html>
Related Story @ TowardsDataScience:
- Build No-code Automated Machine Learning Model with OptimalFlow Web App: https://towardsdatascience.com/build-no-code-automated-machine-learning-model-with-optimalflow-web-app-8acaad8262b1
End-to-end OptimalFlow example in Jupyter notebook:¶
https://github.com/tonyleidong/OptimalFlow/blob/master/tests/notebook_demo.ipynb
or Live Notebook Demo on Binder: