Welcome to OptimalFlow’s Documentation!¶
OptimalFlow is an omni-ensemble and scalable automated machine learning Python toolkit, which uses Pipeline Cluster Traversal Experiments(PCTE) and Selection-based Feature Preprocessor with Ensemble Encoding(SPEE), to help data scientists build optimal models, and automate supervised learning workflow with simpler coding.
OptimalFlow wraps the Scikit-learn supervised learning framework to automatically create an ensemble of machine learning pipelines(Omni-ensemble Pipeline Cluster) based on algorithms permutation in each framework component. It includes feature engineering methods in its preprocessing module such as missing value imputation, categorical feature encoding, numeric feature standardization, and outlier winsorization. The models inherit algorithms from Scikit-learn and XGBoost estimators for classification and regression problems. And the extendable coding structure supports adding models from external estimator libraries, which distincts OptimalFlow ’s scalability out of most of AutoML toolkits.
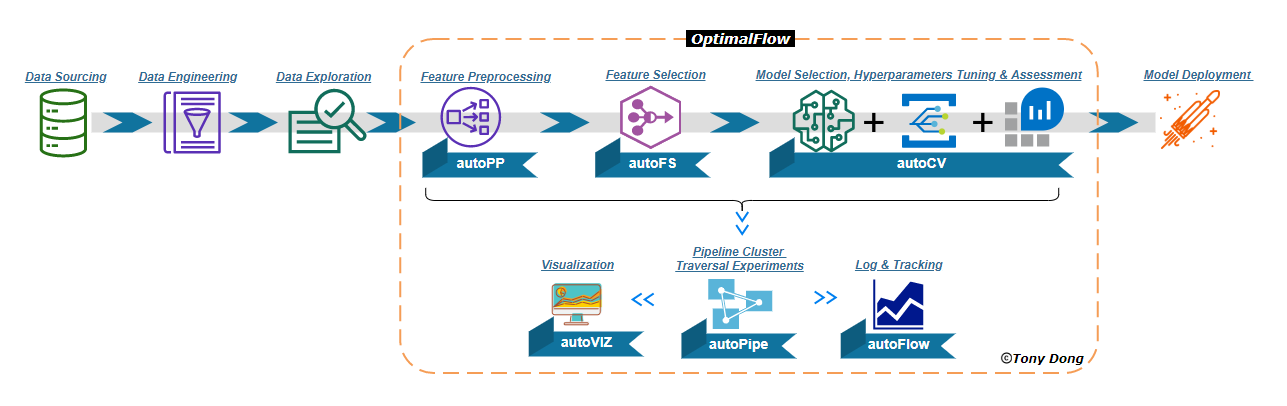
OptimalFlow uses Pipeline Cluster Traversal Experiments as the optimizer to build an omni-ensemble workflow for an optimal baseline model searching, including feature preprocessing/selection optimization, hyperparameters tuning, model selection and assessment.
After the version(0.1.10), it added a “no-code” Web App as an application demo built on OptimalFlow. The web app allows simple click and selection for all of the parameters inside of OptimalFlow, which means users could build end-to-end Automated Machine Learning workflow without coding at all!(Read more details https://optimal-flow.readthedocs.io/en/latest/webapp.html)
Comparing other popular “AutoML or Automated Machine Learning” APIs, OptimalFlow is designed as an omni-ensemble ML workflow builder with higher-level API targeting to avoid manual repetitive train-along-evaluate experiments in general pipeline building.
It reimages the automated machine learning framework by switching the focus from single pipeline components automation to a higher workflow level by creating an automated ensemble pipelines (Pipeline Cluster) traversal experiments and evaluation mechanisms. In another word, OptimalFlow jumps out of a single pipeline’s scope, while treats the whole pipeline as an entity, and automate produce all possible pipelines for assessment, until finding one of them leads to the optimal model. Thus, when we say a pipeline represents an automated workflow, OptimalFlow is designed to assemble all these workflows, and find the optimal one. That’s also the reason to name it as OptimalFlow.
To achieve that, OptimalFlow creates Pipeline Cluster Traversal Experiments to assemble all cross-matching pipelines covering major tasks of Machine Learning workflow, and apply traversal-experiment to search the optimal baseline model. Besides, by modularizing all key pipeline components in reusable packages, it allows all components to be custom tunable along with high scalability.
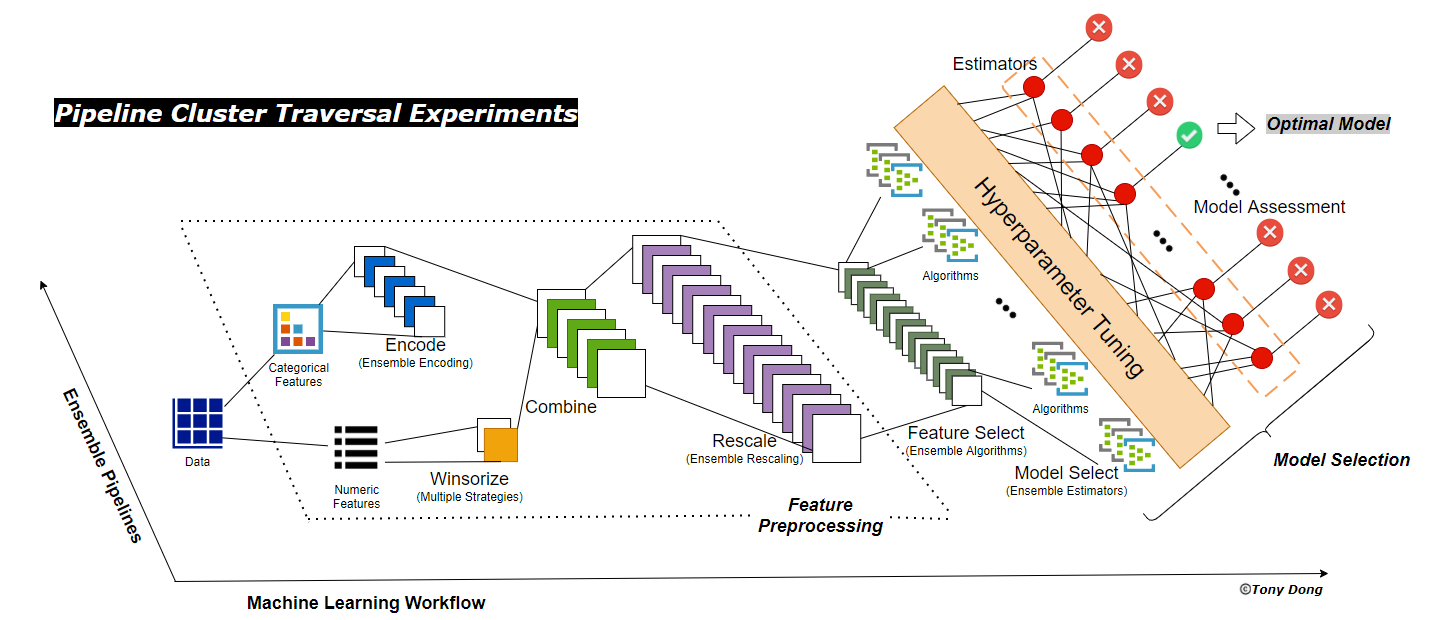
The core concept/improvement in OptimalFlow is Pipeline Cluster Traversal Experiments, which is a theory of framework first proposed by Tony Dong in Genpact 2020 GVector Conference, to optimize and automate Machine Learning Workflow using ensemble pipelines algorithm.
Comparing other automated or classic machine learning workflow’s repetitive experiments using single pipeline, Pipeline Cluster Traversal Experiments is more powerful, with larger coverage scope, to find the best model without manual intervention, and also more flexible with elasticity to cope with unseen data due to its ensemble designs in each component.
In summary, OptimalFlow provides the following benefits to data scientists:
- Easy coding - High-level APIs to implement PCTE, and each machine learning component is highly automated and modularized;
- Easy transformation - Focus on process automation for local implementation, which is easy to transfer current operation and meet compliance restrictions, i.e. pharmaceutical compliance policy;
- Easy maintenance - Wrap machine learning components to well-modularized code packages without miscellaneous parameters inside;
- Light & swift - Easy to transplant among projects. Quick and convenient, to deploy compared with other cloud-based solutions(i.e. Microsoft Azure AutoML);
- Omni ensemble - Easy for data scientists to implement iterated experiments across all ensemble components in the workflow;
- High Scalability - Each module allows addition of add new algorithms easily owing to its ensemble and reusable coding design. PCTE and SPEE make it easier to adapt unseen datasets with the right pipeline;
- Customization - Support custom settings to add/remove algorithms or modify hyperparameters for elastic requirements.
An End-to-End OptimalFlow Automated Machine Learning Tutorial with Real Projects @ TowardsDataScience:
- Part 1: https://towardsdatascience.com/end-to-end-optimalflow-automated-machine-learning-tutorial-with-real-projects-formula-e-laps-8b57073a7b50
- Part 2: https://towardsdatascience.com/end-to-end-optimalflow-automated-machine-learning-tutorial-with-real-projects-formula-e-laps-31d810539102
Other Stories:
- Ensemble Feature Selection in Machine Learning using OptimalFlow - Easy Way with Simple Code to Select top Features: https://towardsdatascience.com/ensemble-feature-selection-in-machine-learning-by-optimalflow-49f6ee0d52eb
- Ensemble Model Selection & Evaluation in Machine Learning using OptimalFlow - Easy Way with Simple Code to Select the Optimal Model: https://towardsdatascience.com/ensemble-model-selection-evaluation-in-machine-learning-by-optimalflow-9e5126308f12
- Build No-code Automated Machine Learning Model with OptimalFlow Web App: https://towardsdatascience.com/build-no-code-automated-machine-learning-model-with-optimalflow-web-app-8acaad8262b1
- Feature Preprocessor in Automated Machine Learning: https://tonyleidong.medium.com/feature-preprocessor-in-automated-machine-learning-c3af6f22f015
Table of contents
- Installation
- Web App
- autoPP Module
- autoFS Module
- autoCV Module
- autoPipe Module
- autoViz Module
- autoFlow Module
- Examples
- Feature preprocessing for a regression problem using autoPP:
- Features selection for a regression problem using autoFS:
- Model selection for a classification problem using autoCV:
- Model selection for a regression problem using autoCV:
- Custom estimators & parameters setting for for autoCV:
- Build Pipeline Cluster Traveral Experiments using autoPipe:
- Pipeline Cluster Traversal Experiments Model Retrieval Diagram using autoViz:
- Pipeline Cluster Model Evaluation Dynamic Table using autoViz:
- Build Pipeline Cluster Traversal Experiments Workflow with Web App:
- End-to-end OptimalFlow example in Jupyter notebook:
- An End-to-End OptimalFlow Automated Machine Learning Tutorial with Real Projects @ TowardsDataScience
- Contributers
- History
- Report Issues